
How fair is the lobste.rs' community regarding self-promo?
Getting involved in petty internet drama is totally not a waste of my time - not if it means I can write some Rust.
lobste.rs is a forum for discussing computing, similar to Hacker News, but with a more narrow focus, and stricter rules around community participation. This makes browsing the forum more pleasant for someone like me who wants to read technical content and not business announcements (I prefer to use LinkedIn for that). It’s probably worth mentioning that despite lurking on the site for years, I don’t have an account on it. This is because the site requires that users be invited by existing users, and I’ve never felt compelled to reach out to some of the people that I sort-of know IRL who have accounts on there (if you’re reading this and you can spare one, please send an invite my way, I’d be over the moon). Anyway, all of this is only tangential to the actual subject of this post - lobste.rs’ self-promo rules and the community’s enforcement of it.
From https://lobste.rs/about:
- Self-promotion: It’s great to have authors participate in the community, but not to exploit it as a write-only tool for product announcements or driving traffic to their work. As a rule of thumb, self-promo should be less than a quarter of one’s stories and comments.
Which is pretty reasonable, except that occasionally when it’s perceived that some (usually new) user is in violation of this guideline, the comments turn into a space where a few users will hem and haw about the rules and accuse the poster of using the site as the comments section for their own blogs. However, it’s always seemed to me that these rules were inconsistent. More well-known authors seemed free to exclusive link to themselves while new users weren’t afforded the same chance to promote their writing. I’ll write more about my opinion on this situation at the end of this article, but I think it’s always important to see if reality matches my perception, so I set out to analyze the behavior of lobste.rs users and determine whether or not there are popular users who are in violation of this guideline. In the spirit of not starting internet crusades (and/or harming my chances of ever participating in the forum), I will not be sharing any actual usernames in the results of my analysis.
Part 1 - gathering data
My plan was to look at the list of users on https://lobste.rs/users, get a
list of users that are active and have non-zero karma, and then for each user,
download the pages /~<USER>/stories*.
This was less trivial than I’d hoped, mainly because lobste.rs doesn’t provide
an API for retrieving data in bulk. The server also aggressively rate limited
any of my attempts to download content. Instead, I opted to get snapshots of the
site via the Wayback Machine.
I poked around my options for retrieving content from archive.org and came
across a fork of
wayback_machine_downloader,
but after playing around with it a bit, I found it a bit cumbersome. In
particular, retrieving lists of snapshotted pages was incredibly slow, and
reading the source, it doesn’t seem like it uses the faster CDX
API,
which also supports doing some filtering server side. Additionally,
with wayback_machine_downloader, I was unable to figure out how to get it to
actually read through the full index and find all user related pages. I was able
to use curl to get a list of all indexed URLs from the CDX server, and then I
implemented my own downloader client in in Rust. My client is very naive and
doesn’t follow redirect requests, and only retries requests up to 3 times, but
in the end out of 18518 active users, 17999 had retrievable data. This number is
good enough for me. I don’t think my analysis will be impacted much even if I
had data for the last 519 users. Not all the data I have is super recent either,
with almost 12000 URLs having timestamps before 2024, but I think that’s also OK
for this endeavor. For what’s it’s worth the full download process still took
somewhere between 3 and 4 hours. This is probably slower than optimum because I
tried to be conservative in my own self-imposed rate limiting and concurrency
limits.
Part 2 - analyzing data
For my analysis I chose to ignore comments made by users and only analyze the histograms of domains that users have posted. It was also useful for me to define a metric for bias - the portion of a user’s posts that link to their most frequently linked to domain. Based of the self-promo rules, we’d expect that most users have a bias of under 0.25 (this based on the assumption that the most frequently linked to domain is owned by or otherwise affiliated with the user. While that might not literally be the case, IMO, it’s equivalent). Here’s what the histogram of number of domains posted per user looks like:
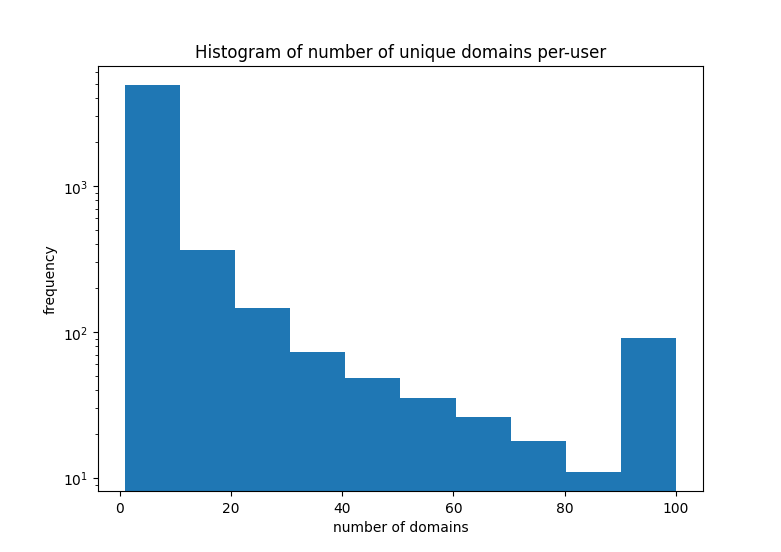
To make the figure look pretty I clamped all values to a maximum of 100. Note that the y-axis is logarithmic, giving us an interesting example of a power-law distribution except that a small fraction of users post a very diverse set of content, breaking the trend.
To do the analysis I continued in Rust to extract aggregate metrics, like bias, number of domains, number of posts, and number of comments per user into JSON which I could then interactively query and visualize using python/matplotlib. One thing that surprised me was that using Rust (and the scraper crate) to parse and extract data from the downloaded HTML was so fast that I didn’t mind just rerunning the script and having it reparse all downloaded files for every user. It was definitely a lot nicer than using something like python/beautifulsoup.
Conclusions/Thoughts
Here’s my findings:
- The average users posts links to 11 unique domains and makes 17 posts.
- The average bias is 0.63, with the median at 0.60.
- Of the 5744 users who’ve made >= 1 post, 4501 have a bias score of > 0.25 (their most frequent domain appears > 1/4 of the time).
- Of the 289 users who’ve made more than 50 posts, 63 have biases above 0.25
- Of those 63, the average bias is 0.49, with a median of 0.39.
So from posts alone, most users are biased towards a specific domain, and on average, probably are breaking the self-promo rules. It’s also worth mentioning that from some random sampling, it seemed that some users had multiple very similar URLs that (in the context of their usernames) seemed to be multiple domains that they controlled. In some cases I found users where some researched showed that their second most linked to domain was their employer or another persona for the same user - I am not attributing either of these cases to shady behavior, there’s perfectly reasonable reasons to have multiple domains, and having seen the posts by some of the users in the latter case, they make it clear when they are posting to content hosted by their own employer or an alias of themselves. But the point I am trying to make is that in some cases the actual bias score should be higher.
This then begs the question, do things look differently if we include comments? Unfortunately, the answer is a bit murky, mainly because the comment snapshots seem to be much older than the post snapshots, and so it unfairly skews the results and implies that most users post way more than they comment, so I don’t know if I want to share the raw data I’ve collected here. All I will say is that from the data I’ve gathered, including comments suggests that users with high post counts and high biases do not comment more frequently than they post.
Some users are likely deeply in violation of the self-promo guidelines, but the community seems to turn a blind eye to it. I think the rules as they are help keep the quality of the site high. And to be fair, for the more popular users who’re guilty of violating the self-promo rules, I would not classify their posts as spammy. It’s high-quality, well-written, and engaging content that drives interesting discussions. But I think the self-promo rule enforcers should relax a little. Ideally, self-linking should be gated behind a karma score, but enforcing that automatically sounds impossible (how do you know which domains are part of the user’s “self”). In lieu of that, I’d like to see this rule enforced as a tool to combat low-effort spam or solicitation, but I don’t think bloggers who’ve taken the time to write content that they believe is worthy of discussion should be chastised. You can always just keep scrolling.